PerimeterX(前段时间被 Human Security 收购)是最重要的反爬虫程序解决方案之一,与 Cloudflare、Datadome 和 Kasada 一起被 Forrester 在其行业报告中认可。
在深入研究我所研究的解决方案的技术细节之前,让我们尝试更多地了解 PerimeterX
什么是 PerimeterX,您如何检测它?
如前所述,PerimeterX Bot Defender(又名 HUMAN Bot Defender)是最著名的反机器人解决方案之一,被 Crunchbase、Zillow、SSense 等网站使用。
通过浏览文档,我们可以了解它的架构由三个不同的组件组成:
HUMAN Sensor:插入到您网站上的 JavaScript 代码段,用于将 HUMAN Sensor 加载到您的浏览器。Sensor 收集和发送数据以分析用户和设备行为以及网络活动。它评估设备和应用程序的真实性,并跟踪用户行为和交互。
HUMAN Detector:一个基于云的组件,使用机器学习和行为分析实时评估传感器和执行器数据,以创建风险评分。此风险评分可识别用户是否为恶意用户,并以安全加密的令牌发送回用户的设备。
HUMAN Enforcer:安装在您选择的 Web 应用程序、负载均衡器或 CDN 上的轻量级模块。它负责 HUMAN 解决方案的实施功能。
每个安装都可以配置不同的安全层和选项。
根据我的经验,最常见的启用选项之一是 Human Challenge,即 PerimeterX 典型的大“按住按钮”。
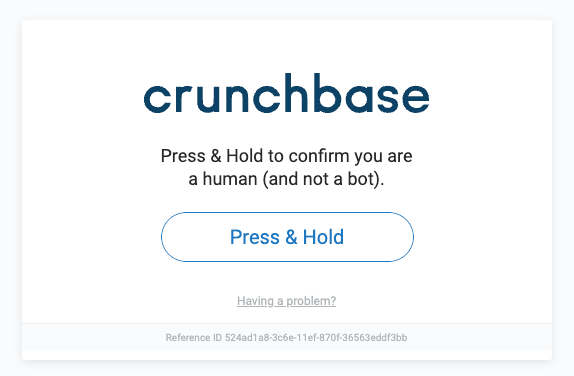
作为替代方案,可以在网站上使用 Google ReCAPTCHA。
在这两种情况下,PerimeterX bot Defender 都会向浏览器发出无形的挑战,以检测爬虫配置或行为中的任何危险信号。
如果网站需要在范围的有限部分(例如一些稀有商品或结帐流程)上提供额外保护,则可以激活一个更强大的机器人检测系统,称为 Hype Sale。
在这种情况下,使用更多资源消耗(且解决速度较慢)的挑战来检测机器人,这也是为什么这种方法不能应用于整个网站的原因,除非对用户体验进行严重惩罚。
我们如何使用 PerimeterX 检测网站?
与往常一样,最简单的方法是使用 Wappalyzer 浏览器扩展,即使应该始终仔细检查其结果,因为它们的数据库可能无法更新。
检测 PerimeterX 非常简单,既可以查看网站的 cookie ,也可以查看它进行的网络调用。
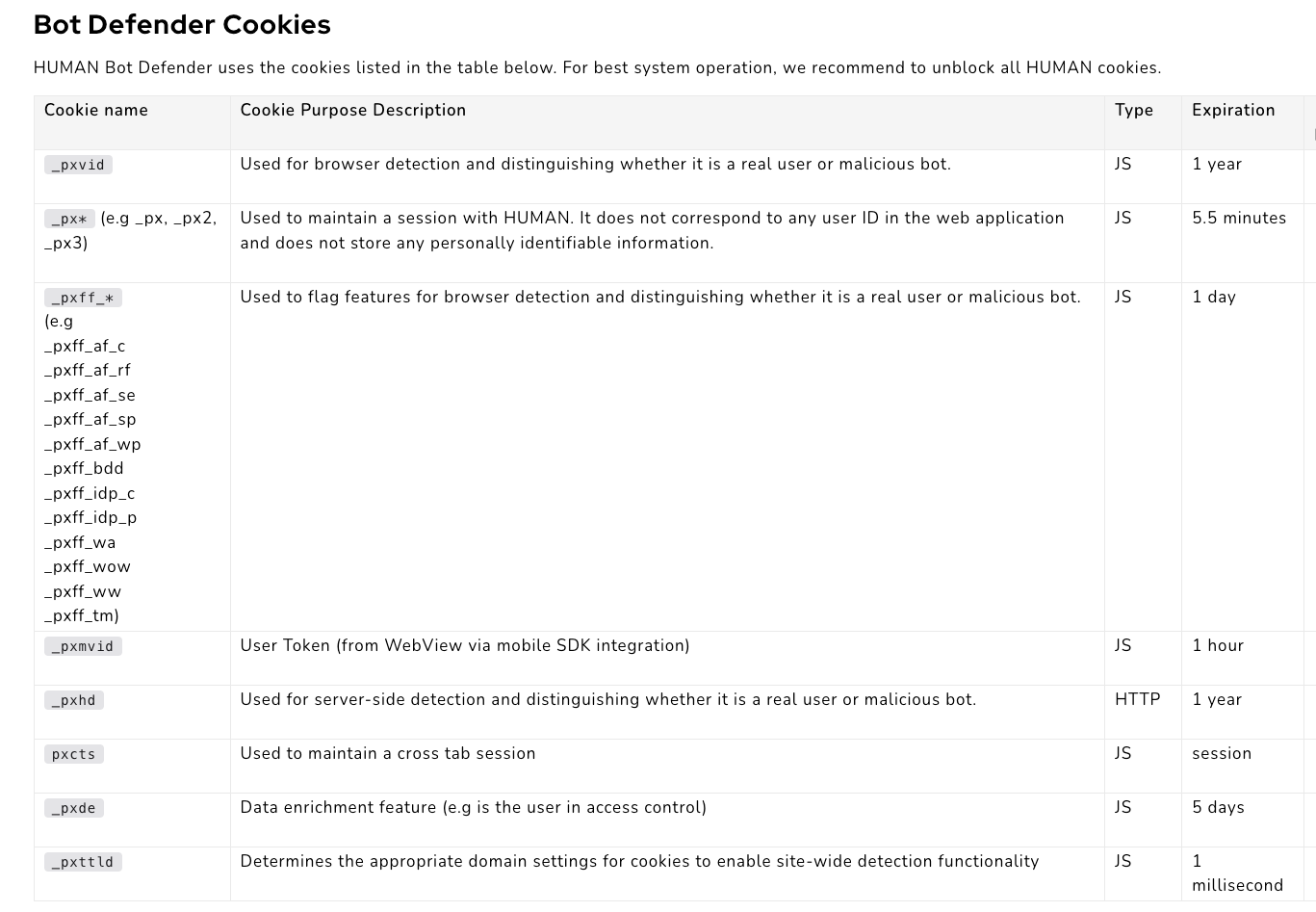
始终来自 PerimeterX 文档网站,这是您应该在使用它的网站上看到的 cookie 列表。
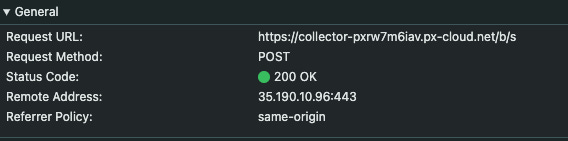
另一种方法,稍微困难一些,是在开发人员的工具中打开 network 选项卡,并查找对 PerimeterX 相关域的请求,例如:
perimeterx.net
px-cdn.net
px-cloud.net
pxchk.net
px-client.net如下面的真实案例
现在我们已经了解了如何检测 PerimeterX,让我们了解如何绕过它来抓取公共数据。
使用浏览器进行首次测试
让我们寻找一个仅受 Perimeterix 3 保护的网站,这样我们就可以确定我们的解决方案。
理想情况下,我们应该获得 _px3 cookie,并且不应安装其他反机器人软件。
经过一番搜索,设计的目标网站被选中了:Crunchbase!


由于网站有一个开放部分,然后在登录页面后面有更多内容,因此我们的测试范围将仅是可用的公共信息,无需登录。我强烈建议您不要使用这些(或其他)技术来抓取付费数据,否则您可能会遇到与违反服务条款和知识产权相关的问题。
鉴于这些应有的前提,让我们研究一下简单地以隐身模式浏览网站可以做什么,什么不能。
第一个测试包括以隐身模式直接从浏览器打开公司页面:例如,我们可以打开 Databoutique.com 页面,但我们被 Human Challenge 阻止了。
因此,第二个测试是打开 Crunchbase 主页,然后打开 Databoutique 页面。
在这种情况下,我们成功了!
当我们创建爬虫时,我们必须考虑到我们不能启动一个全新的浏览器会话并直接进入 Crunchbase 公司简介页面,但我们至少应该在之前打开主页(好吧,剧透:我们会看到这还不够)。
什么不起作用
我已经尝试了最简单的方法,所以使用 Scrapy spider(也添加了 Scrapy_impersonate 包)我尝试打开 Google,然后是 Crunchbase 主页,然后是公司页面,但没有成功。
def start_requests(self):
url='https://www.google.com/'
yield Request(url, callback=self.get_home_page, headers=self.HEADER, meta={'impersonate': 'chrome110'}, dont_filter=True)
def get_home_page(self, response):
url='https://www.crunchbase.com/'
yield Request(url, callback=self.read_company_page, headers=self.HEADER, meta={'impersonate': 'chrome110'}, dont_filter=True)
def read_company_page(self, response):
url='https://www.crunchbase.com/organization/luma-ai'
yield Request(url, callback=self.end_test, headers=self.HEADER, meta={'impersonate': 'chrome110'}, dont_filter=True)
def end_test(self, response):
print("Test ended")
除非您使用带有 JS 渲染的解阻器,否则您将无法使用简单的 Scrapy 抓取工具绕过网站带来的挑战。我们需要像 Playwright 这样的浏览器自动化工具。
与往常一样,如果您想查看代码,可以访问 GitHub 存储库,可供付费读者使用。您可以在文件夹 56.PERIMETERX3 中找到此示例
如果您是其中之一但无法访问它,请写信给我 pier@thewebscraping.club 以获取它。
我第一次在本地计算机上尝试使用 Playwright
我尝试的第一件事是使用我默认的 Playwright 配置,直接从其 URL 加载 Crunchbase 公司页面。
def run_chrome(playwright):
CHROMIUM_ARGS= [
'--no-first-run',
'--disable-blink-features=AutomationControlled',
'--start-maximized'
]
# Get the screen dimensions
browser = playwright.chromium.launch(channel="chrome", headless=False,slow_mo=200, args=CHROMIUM_ARGS,ignore_default_args=["--enable-automation"])
context = browser.new_context(
no_viewport=True
)
page = context.new_page()
page.goto('https://www.crunchbase.com/organization/databoutique-com', wait_until="commit")你猜怎么着?
再次按住!
这不是指纹的问题,因为我是从自己的 Mac 启动我的抓取工具,也不是 IP 问题,因为我在家里,使用一台干净的 Mac。
那么,问题可能是什么呢?
然后,我想起了使用浏览器测试网站时的行为。
我在本地计算机上第二次尝试使用 Playwright
即使使用常规浏览器,如果实例是新的(在我的情况下是隐身模式),我们也无法直接访问公司页面。
我刚刚稍微修改了我的抓取工具,按顺序打开:Google 主页、Crunchbase 主页,然后才打开公司页面。而且它正在发挥作用!
您可以在存储库中文件test_local.py文件夹 56.PERIMETERX3 中找到该脚本。
但是,在 AWS 计算机上运行时,此基本脚本是否足够?
我的第三次尝试:AWS 上的 Playwright
在对 AWS 测试进行编码之前,让我们研究一下从 AWS 机器浏览网站时网站的行为,重新创建与爬虫相同的请求序列。
使用 Chrome,我可以打开 Google,但在加载 Crunchbase 主页时被 HUMAN 质询阻止。无论如何,我都尝试加载公司页面,令我惊讶的是,它们被正确呈现了。
这些事实使我得出两个考虑:
至少对于 Crunchbase 来说,不需要任何代理,因为甚至可以从 AWS IP 获得公共数据
主页上有一种指纹检查,但公司的主页上没有。
作为对这一理论的证实,本地爬虫也可以在 AWS 上运行,显示 HUMAN 质询而不是主页,但随后能够加载公司的质询。
然后,我将浏览器从 Google 切换到 Brave,它有一些机制可以混淆其部分指纹,并再次测试了爬虫(文件 test_aws.py)。
只需这样做,即使是主页也能正确加载,因此切换到 Brave 就足以绕过这个挑战。
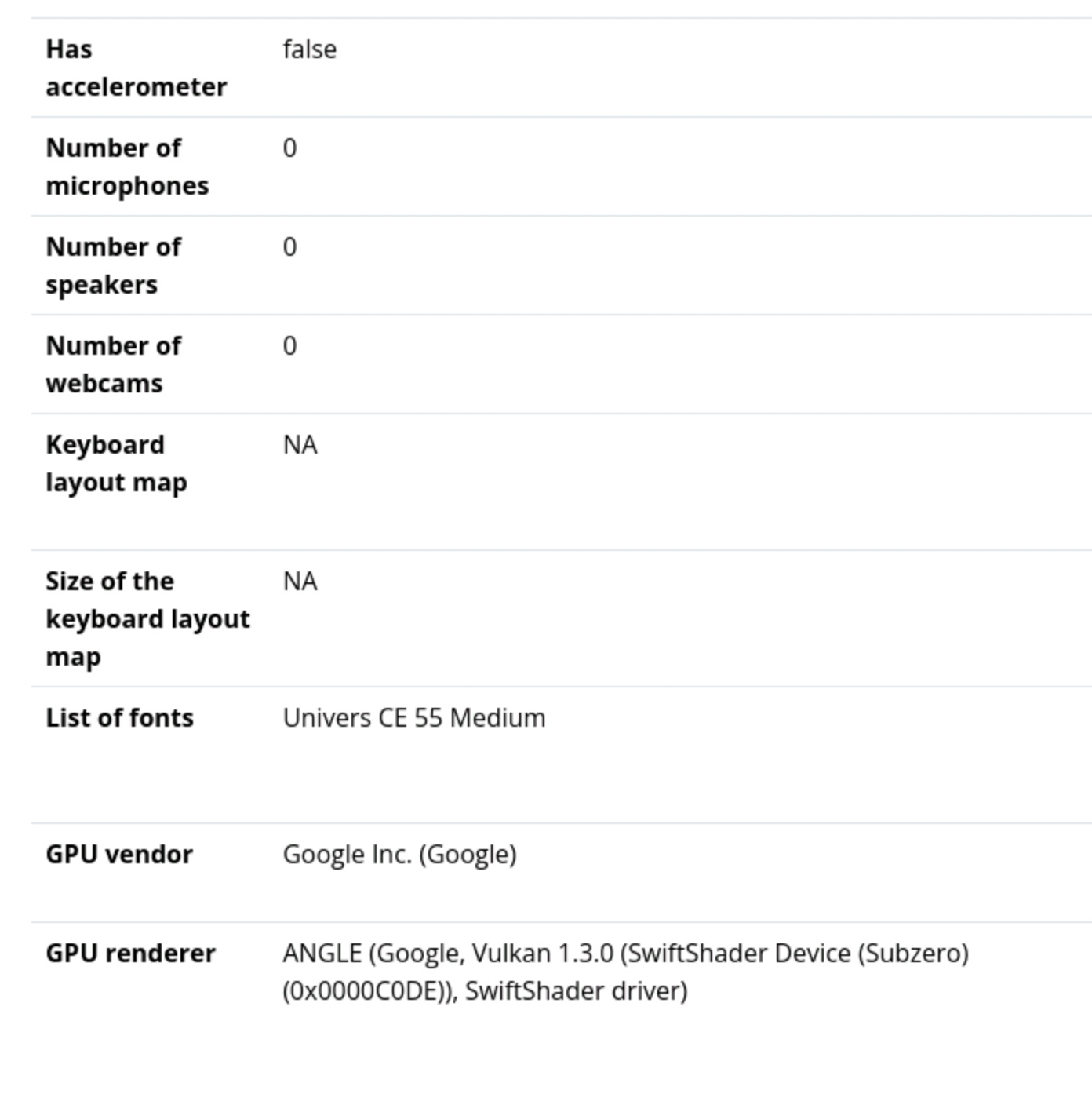
考虑到 Brave 没有掩盖最基本的危险信号,比如 WebGL 渲染器或音频/视频设备的数量,至少在 Crunchbase 上我们可以说浏览器指纹的控制并没有那么严格。
最后的考虑
从 Crunchbase 上的 PerimeterX 安装中,我们可以了解到:
我们需要一个浏览器自动化工具来完成 JS 挑战
数据中心 IP 上的过滤器并不总是处于活动状态,因为在这种情况下,我们不需要任何代理
对 Scraper 进行的行为分析可能非常基本
很少有浏览器 API 用于检测爬虫,即使是最常见的 API (如 webGL 渲染器和音频/视频设备的数量)也是如此。
这并不意味着每个网站的行为都相同。过滤器和检测规则可以由网站所有者自定义,从而使解决方案或多或少有效。
Web Scraping 炉边谈话
我正在准备一组名为 The Web Scraping Fireside Chat的视频,我将在其中采访 Web 抓取领域的关键人物。我打算揭示网络抓取的几个不同观点和方面。
作为付费读者,您将有机会参加录制会议并提出您的问题。
以下是未来几周已确认电话会议的议程:
Nick Rieniets - Kasada 首席技术官 7 月 18 日星期四 - 中午 12:00 (GMT+2)
加盟链接: https://riverside.fm/studio/the-web-scraping-fireside-chat--nick-rienets---cto-kasada
关于反爬虫程序行业及其这些年的发展。
Antoine Vastel - Datadome 研究副总裁 7 月 23 日星期四 - 下午 4:00 (GMT+2)
第二集专门讨论反机器人,在这种情况下,我们谈论的是反机器人的工作原理,重点是指纹识别。
您将通过邮件或 Discord 服务器上的频道 #the-web-scraping-fireside-chat 接收更新,仅对付费读者可见。
Comments
Post a Comment