每天都会宣布新的 AI 抓取工具。在我在网络抓取行业的整个职业生涯中,我从未见过这样的时刻。人们对自动化任务(如收集数据)非常感兴趣,并且该领域的一些初创公司第一次被 YCombinator 接受。
在这场竞赛中,参赛者是开源项目、无代码工具,当然还有在其产品后端使用 AI 的行业中的成熟公司。
为了提供更广阔的视野(这肯定不是详尽无遗的),我决定使用两个驱动程序对所有这些工具进行分类:
使用公开可用的 AI 模型(通常是 GPT 等 LLM),或者使用内部开发的 AI 模型
神奇的地方发生:我是否需要在我的计算机上运行模型,还是在云端进行细化?
免責聲明
我尽我所能在其网站上包含所有明确声称使用 AI 的工具,但可以肯定的是,我错过了某人。如果您正在开发地图中未包含的 AI 抓取工具,请在评论部分写下来,我会添加它。
此外,一些商业工具声称在他们的引擎中使用 AI,但我无法确定它是否属实,所以我依赖于我在他们的网站上看到的内容。
我的研究结果是下面的地图。
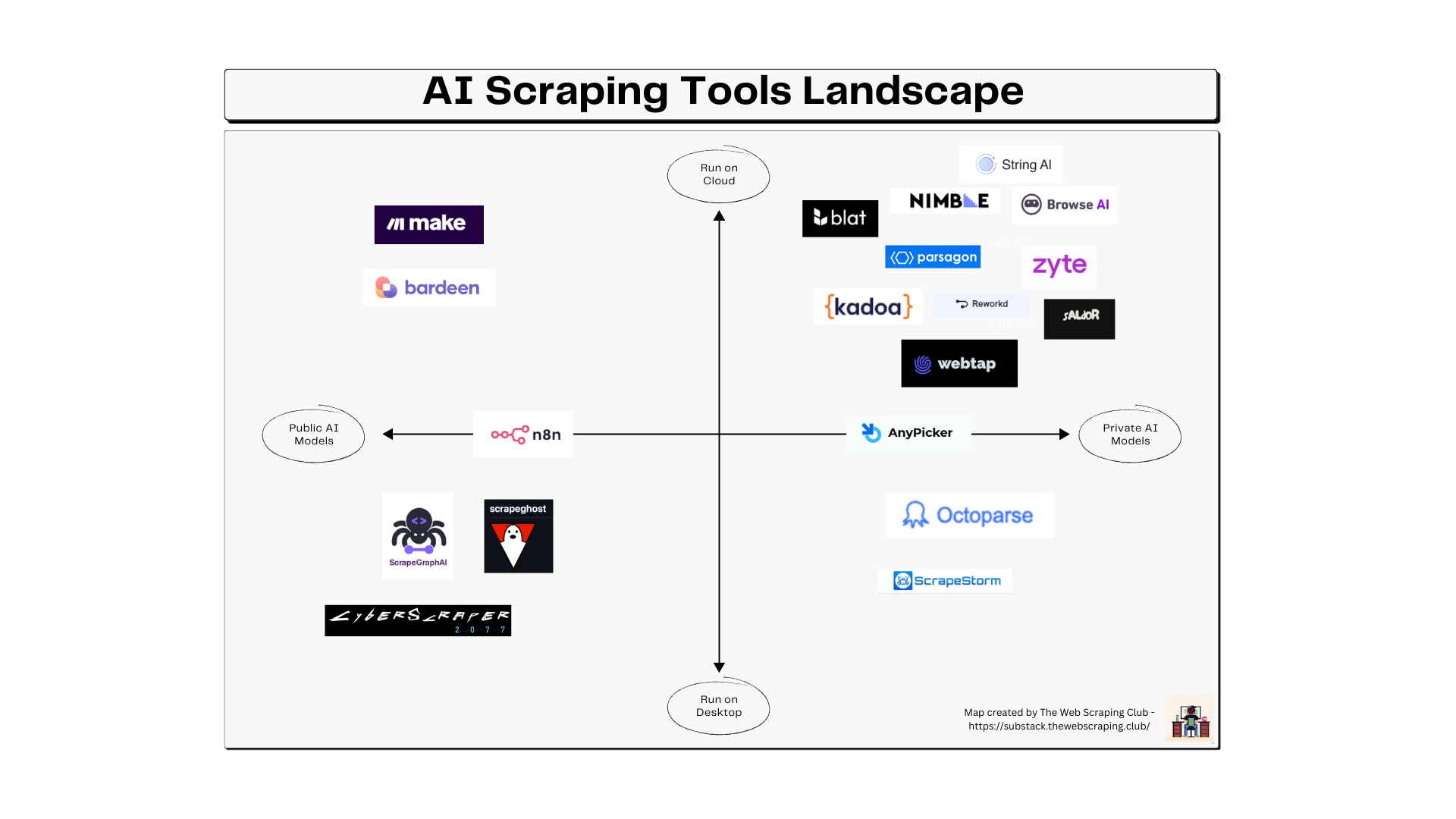
在云上运行的私有 AI 模型
在此类别中,我们找到了创建爬虫并将输出映射到特定数据结构的所有工具,这些工具开发了内部 AI 解决方案,并且可以与 API 或通过 Web 一起使用。我不需要在我的计算机上下载客户端或托管 LLM 模型并运行它。
我们可以在这个象限中找到:
Nimble 用于抓取的不同 API 工具,从垂直工具到 SERP 到电子商务再到通用 Web API
Zyte API,它利用 Zyte 在 Web 抓取和 AI 方面的经验,以编程方式编写爬虫以满足您的需求。
Browse.AI,您可以在其中有一个点击式界面来选择所需的输出数据,Browse.AI 在 Excel 电子表格中返回网站的完整抓取
Paragon 在 YC 的支持下,他们基本上使用抓取技术和 AI 来监控网络并提供数据馈送
由 YC 支持的另一家公司 Reworkd 正在使用 LLM 创建端到端数据提取管道。
Kadoa 是一个 Web 界面,可让您创建在无代码环境中抓取网站的工作流程
Saldor 再次在 Summer 24 批次中得到 YC 支持的公司,它创建了一个抓取工具,在给定提示和目标网站的情况下,它会提取所需的数据。
Blat.ai,该工具旨在在几分钟内交付生产就绪的 Web 抓取代码
WebTab,一个类似 ChatGPT 的界面,用于使用自然语言的提示进行抓取
String AI,一种甚至可以抓取受反机器人保护的网站的工具
私有 AI 模型,使用客户端
在这里,我们找到了需要客户端安装在您的机器上的工具,并使用某些 AI 模型来理解网站的 HTML 代码
我们可以在这个象限中找到:
Octoparse,它最近在其工具中添加了一些 AI 用于抓取
AnyPicker,在这种情况下,您需要安装一个 Chrome 扩展,HTML 映射的执行将在云中进行
ScrapeStorm 与 Octoparse 类似,您可以下载客户端并在向工具提供一些说明后获取所需的数据
在云上运行的公共 AI 模型
在这个类别中,我们拥有所有使用 LLM 进行抓取的工具,而无需用户下载任何客户端。
Bardeen.Ai,不仅仅是一个抓取工具,它还是一个自动化框架,具有指向不同软件的多个连接器。其中一个用例是,您从 Web 获取数据并使用 LLM 对其进行详细说明,从而创建在云上运行的数据管道
Make.com,以前称为 Integromat,其工作方式与 Bardeen 类似,但具有数千种不同的连接器
N8N 是 Make.com 和 Bardeen 的免费开源替代品。它既可以是自托管的,也可以是云上的。
公共 AI 模型、自托管解决方案
在最后一个象限中,我们有使用公共 LLM 的解决方案,需要安装在您的设备中。
ScrapeGraph-AI,如果您关注此时事通讯,您已经阅读了一些使用它使用 GPT 和本地模型进行抓取和编写抓取程序的文章。这是最新的
Cyber Scraper 2077,我喜欢这个名字,它似乎是一个有趣的解决方案,用于抓取和使用 LLM 解析数据。我想您很快就会在本期通讯中看到一篇关于它的文章。
ScrapeGhost,同样是一个使用 GPT 解析数据的 OSS

您有什么推荐的工具吗?您是否尝试过地图中提到的一些工具?欢迎在评论区写下您的印象,让我知道您的想法!
Comments
Post a Comment