Traditional freelancing gigs
The traditional way to monetize your web scraping skill is by selling your services on traditional marketplaces like Upwork, Fiverr, and Freelancer.com. Only on Upwork today can we find more than 1800 job requests with the words “web scraping”, which is an interesting number that makes us understand the size of the market and the interest in web scraping in general.
Also on our Discord Server, there is a channel dedicated to web scraping jobs and freelancing offers, in case you’re interested.
Pros and cons of freelancing
Freelancing could be remunerative since the demand for web data is rising and more companies are looking for it, without having the skills in-house.
But it’s not all fun and money: you need to find available gigs, beat your competitors by convincing the employer, and deal with him at the right price.
It also involves understanding the requirements of the project, something not always easy, and estimating its potential costs.
Sell your agent on the Apify marketplace
Another interesting business model comes from Apify. Apify is a platform where you can build, deploy, and monitor your scrapers, using different technologies.
The platform provides easy access to compute instances, called actors, request and result storages, proxies, scheduling, webhooks, and more. It’s an end-to-end solution for developing, deploying, and scheduling.
Whether you’re a developer using Node.js or Python, you can use the different integrations provided by Apify for the most well-known frameworks and tools, like Playwright or the brand-new Scrapy integration, launched in the past weeks.
One of the features I like most about the Apify platform is the store, where you can list the actors you’ve created and monetize them.

As mentioned in the Apify Docs, you have different pricing models for your actors:
free - you can run the Actor freely, and you only pay for platform usage the Actor generates.
rental - same as free, but in order to be able to run the Actor after the trial period, you need to rent it from the developer and pay a flat monthly fee on top of the platform usage that the Actor generates.
paid per result - you do not pay for the platform usage that the Actor generates but only for the results it produces.
When you choose to make your Actor rental, you will specify the length of the free trial and a monthly rental price. Any user that wants to use your Actor will need to first activate the free trial, and once that's concluded, they will be charged the monthly rent set by you. Note that after the free trial, the user will need to have one of Apify's paid plans to be able to pay the monthly rental and use the Actor further.
As the developer of the scraper, you’ll get 80% of the monthly rental fee, while the user pays the rental fee and Apify’s paid plan.
If you make your Actor pay-per-result instead, you will set the price per 1,000 results, and users will be charged for your Actor solely based on the number of results your Actor produces. That's your revenue. The underlying platform usage the Actor generates is your cost. Your profit which is then paid to you is computed as 80% of the revenue minus the costs, i.e. (0.8 * revenue) - costs = profit. This profit is also paid out monthly.
Sell your data on Databoutique.com
A third option for monetizing your web scraping skills is to sell directly the data you extracted on data marketplaces like Data Boutique (disclaimer: I’m one of the co-founders).
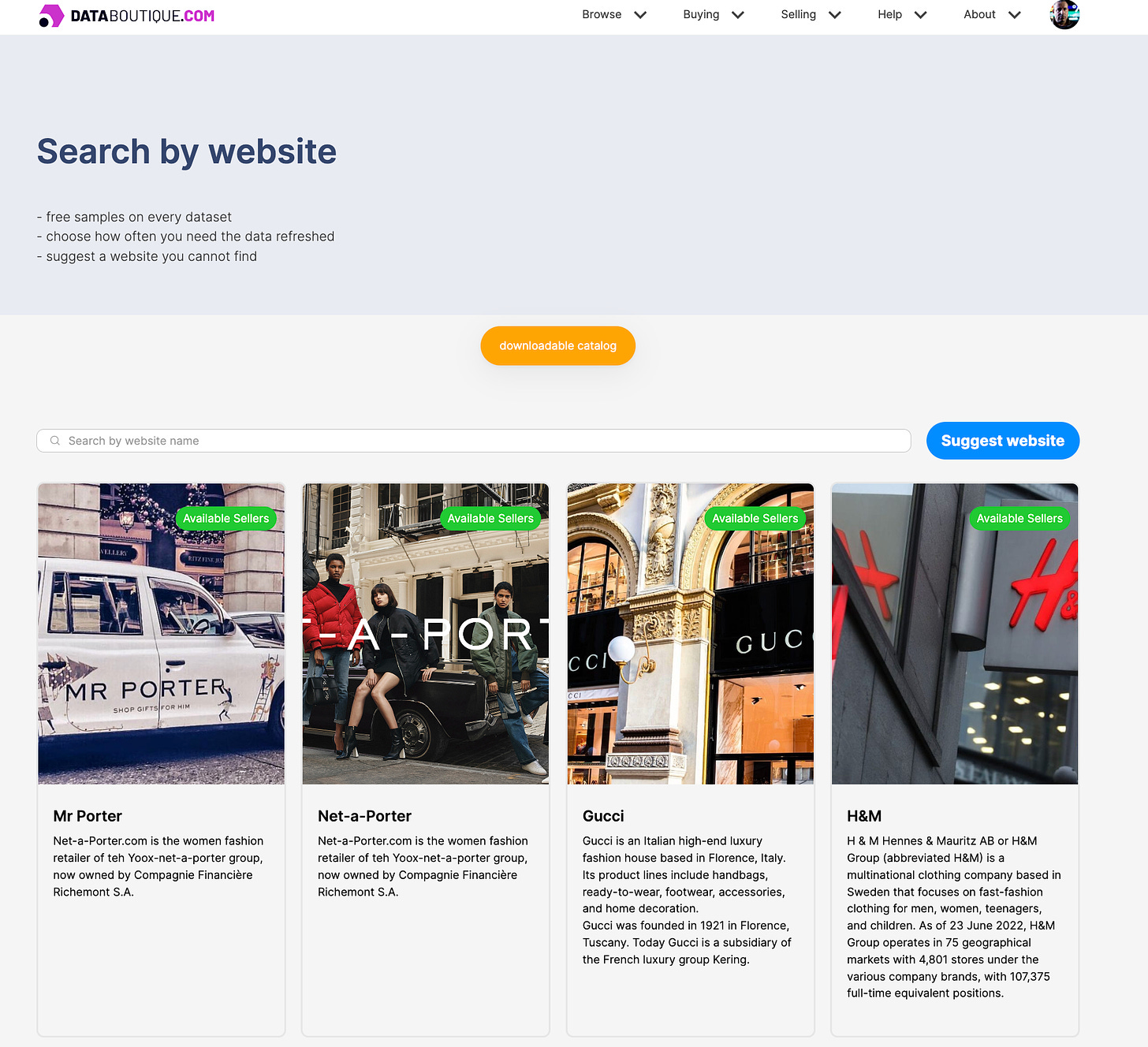
The idea behind Data Boutique is to pool together the supply of web-scraped data in a marketplace where to collect its demand.
By standardizing the data structure using different data models, the data buyer could select different datasets from a pool of vendors that can be stacked up together since they have the same structure.
The data quality is ensured by a mix of automatic controls made by the platform and some manual data sampling made by a peer-to-peer network.
As a seller, the process to list your data is straightforwardrd: after registering to the platform, you can look for open bids, which are binding requests from buyers willing to receive some dataset not already on the platform or apply for selling any listed dataset. Also, if you’re willing to sell a dataset for a website that is not yet listed, you could suggest it from the catalog page, and, after a short review, it will be soon available if requirements are met.

In any case, when you decide to sell a dataset, you need to complete a due diligence questionnaire, prepare the documentation, add some quality checks and set the price per download.

You can set the price you feel it’s the best, considering that for every download you will receive 70% of it but also that if the price is too high, people needing your dataset could choose to scrape it by themselves.
After creating the scraper with any technology you’re proficient in (maybe you can create an Apify actor and monetize even from that), you just need to send data to an AWS S3 bucket. If quality controls are passed, the data will become immediately available for the potential buyers, adding a new revenue stream for you. You just need to keep the data updated on a regular basis and you’re on the road to becoming a new millionaire!

Ai generated image of a rich man burning money
My two cents (literally)
Jokes apart, the web scraping industry is evolving fast and so are all the careers and skills needed for it.
Today, there are more opportunities than in the past to make some money with your scraping skills without a traditional 9 to 5 job. The demand for data is skyrocketing, thanks to AI and the digitalization of the economy, and services like Apify Store and Databoutique.com are providing fast access to web data while giving scraping experts new opportunities of monetization.
The traditional way to monetize your web scraping skill is by selling your services on traditional marketplaces like Upwork, Fiverr, and Freelancer.com. Only on Upwork today can we find more than 1800 job requests with the words “web scraping”, which is an interesting number that makes us understand the size of the market and the interest in web scraping in general.
Also on our Discord Server, there is a channel dedicated to web scraping jobs and freelancing offers, in case you’re interested.
Pros and cons of freelancing
Freelancing could be remunerative since the demand for web data is rising and more companies are looking for it, without having the skills in-house.
But it’s not all fun and money: you need to find available gigs, beat your competitors by convincing the employer, and deal with him at the right price.
It also involves understanding the requirements of the project, something not always easy, and estimating its potential costs.
Sell your agent on the Apify marketplace
Another interesting business model comes from Apify. Apify is a platform where you can build, deploy, and monitor your scrapers, using different technologies.
The platform provides easy access to compute instances, called actors, request and result storages, proxies, scheduling, webhooks, and more. It’s an end-to-end solution for developing, deploying, and scheduling.
Whether you’re a developer using Node.js or Python, you can use the different integrations provided by Apify for the most well-known frameworks and tools, like Playwright or the brand-new Scrapy integration, launched in the past weeks.
One of the features I like most about the Apify platform is the store, where you can list the actors you’ve created and monetize them.
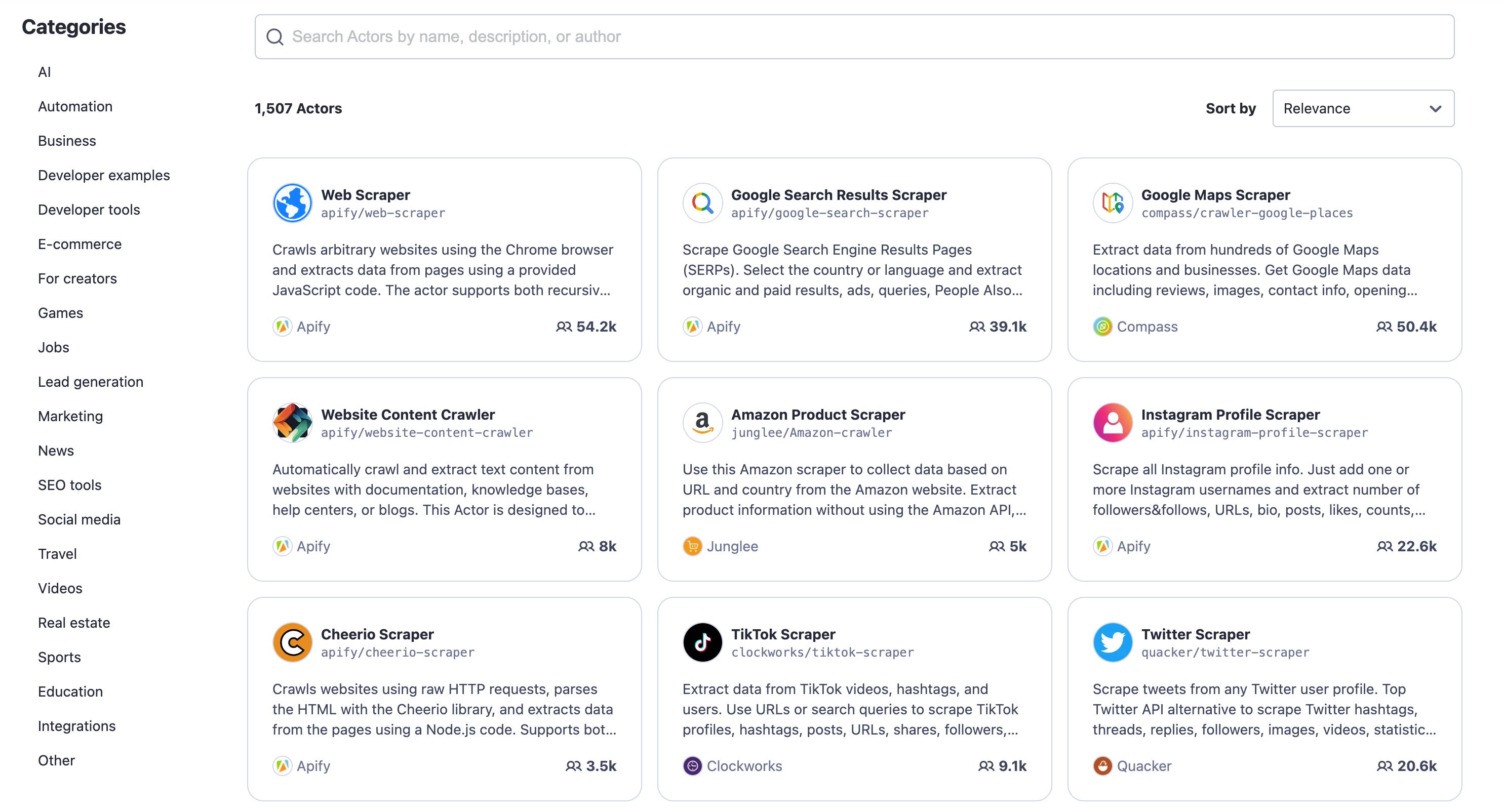
As mentioned in the Apify Docs, you have different pricing models for your actors:
free - you can run the Actor freely, and you only pay for platform usage the Actor generates.
rental - same as free, but in order to be able to run the Actor after the trial period, you need to rent it from the developer and pay a flat monthly fee on top of the platform usage that the Actor generates.
paid per result - you do not pay for the platform usage that the Actor generates but only for the results it produces.
When you choose to make your Actor rental, you will specify the length of the free trial and a monthly rental price. Any user that wants to use your Actor will need to first activate the free trial, and once that's concluded, they will be charged the monthly rent set by you. Note that after the free trial, the user will need to have one of Apify's paid plans to be able to pay the monthly rental and use the Actor further.
As the developer of the scraper, you’ll get 80% of the monthly rental fee, while the user pays the rental fee and Apify’s paid plan.
If you make your Actor pay-per-result instead, you will set the price per 1,000 results, and users will be charged for your Actor solely based on the number of results your Actor produces. That's your revenue. The underlying platform usage the Actor generates is your cost. Your profit which is then paid to you is computed as 80% of the revenue minus the costs, i.e. (0.8 * revenue) - costs = profit. This profit is also paid out monthly.
Sell your data on Databoutique.com
A third option for monetizing your web scraping skills is to sell directly the data you extracted on data marketplaces like Data Boutique (disclaimer: I’m one of the co-founders).

The idea behind Data Boutique is to pool together the supply of web-scraped data in a marketplace where to collect its demand.
By standardizing the data structure using different data models, the data buyer could select different datasets from a pool of vendors that can be stacked up together since they have the same structure.
The data quality is ensured by a mix of automatic controls made by the platform and some manual data sampling made by a peer-to-peer network.
As a seller, the process to list your data is straightforwardrd: after registering to the platform, you can look for open bids, which are binding requests from buyers willing to receive some dataset not already on the platform or apply for selling any listed dataset. Also, if you’re willing to sell a dataset for a website that is not yet listed, you could suggest it from the catalog page, and, after a short review, it will be soon available if requirements are met.

In any case, when you decide to sell a dataset, you need to complete a due diligence questionnaire, prepare the documentation, add some quality checks and set the price per download.

You can set the price you feel it’s the best, considering that for every download you will receive 70% of it but also that if the price is too high, people needing your dataset could choose to scrape it by themselves.
After creating the scraper with any technology you’re proficient in (maybe you can create an Apify actor and monetize even from that), you just need to send data to an AWS S3 bucket. If quality controls are passed, the data will become immediately available for the potential buyers, adding a new revenue stream for you. You just need to keep the data updated on a regular basis and you’re on the road to becoming a new millionaire!
Ai generated image of a rich man burning money
My two cents (literally)
Jokes apart, the web scraping industry is evolving fast and so are all the careers and skills needed for it.
Today, there are more opportunities than in the past to make some money with your scraping skills without a traditional 9 to 5 job. The demand for data is skyrocketing, thanks to AI and the digitalization of the economy, and services like Apify Store and Databoutique.com are providing fast access to web data while giving scraping experts new opportunities of monetization.
Comments
Post a Comment