source: Best Web Scraping Tools to Check Out in 2024 (Updated) - Scraping Dog
Web Scraping as the name suggests is the process of extracting data from a source on the internet. With so many tools, use cases, and a large market demand, there are a couple of web scraping tools to cater to this market size with different capabilities and functionality.
I have been web scraping for the past 8 years and have vast experience in this domain. In these years, I have tried and tested many web scraping tools (& finally, have made a tool myself too).
In this blog, I have handpicked some of the best web scraping tools, tested them separately, and ranked them.
4 Types of Web Scraping Tools
With different levels of experience, users may have the web scraping tools that can be divided into different categories.
1. Web Scraping APIs: This category is ideal for users with some programming knowledge and who prefer a more hands-on approach but still want some convenience.
These APIs allow users to integrate web scraping functionalities directly into their applications or scripts. They often provide a high level of customization and can handle complex scraping tasks relatively easily.
2. No-Code Web Scraping Tools: This category is perfect for users without programming skills or who prefer a more straightforward, user-friendly approach. These tools typically offer a graphical user interface (GUI) where users can easily select data they want to scrape through point-and-click methods.
They are very accessible and are great for simpler scraping tasks or for users who need to scrape data quickly without delving into code.
3. Web Scraping Tools for SEO: These are the tools specifically designed for digital marketing and SEO professionals. Focused on extracting and analyzing data from individual websites to assess SEO-related aspects.
Key functionalities include a thorough inspection of website content for duplication issues, especially when similar content appears on multiple pages, which can affect search engine rankings.
These tools typically concentrate on analyzing a single website at a time, providing targeted insights into its SEO
performance and identifying areas for optimization. This focused approach allows for a detailed understanding of a specific site’s SEO health.
4. Building Scraping Tools using Programming Languages – This category suits users with programming expertise who need highly tailored solutions. Languages like Python, JavaScript, and Ruby, with libraries such as BeautifulSoup, Scrapy, Puppeteer, and Cheerio, offer a high degree of customization.
| Category | Target Users | Key Features | Use Cases |
|---|---|---|---|
| Web Scraping APIs | Users with some programming knowledge | High level of customization, integration into applications/scripts, handles complex tasks | Complex data extraction, automation in scraping |
| No-Code Web Scraping Tools | Users without programming skills | User-friendly GUI, point-and-click data selection, accessible | Simple scraping tasks, quick data extraction |
| Web Scraping Tools for SEO | Digital marketing and SEO professionals | Focuses on individual websites, analyses SEO aspects like content duplication | SEO performance analysis, optimising website SEO |
| Tools built using the programming language | Users with programming expertise | High degree of customization, use of specific programming languages and libraries like BeautifulSoup, Scrapy, etc. | Highly tailored scraping solutions, extensive data manipulation |
5 Best Web Scraping APIs
Scrapingdog
- Zillow Scraper API
- LinkedIn Profile Scraper API
- LinkedIn Job Scraper API
- Google Search Result Scraper API
- Twitter Scraper API
- Indeed Scraper API
Smartproxy Web Scraping API
Smartproxy, known for its leading proxy-providing service, has expanded its offerings and has now an API for web scraping. This development positions them as a versatile tool for those looking to build effective scrapers. With one of the largest pools of data centers and residential proxies, their service ensures broad compatibility across various websites.
While primarily acclaimed for its expansive proxy network, Smartproxy has now also come into dedicated scraping APIs, especially for prominent sites like Amazon and Google, which is a significant enhancement to their services. It’s important to note, though, that while their proxies generally perform well, there can be variability in success rates when scraping certain domains like Indeed and Amazon.
Brightdata
Brightdata, previously known as Luminati, is a prominent player in the proxy market, offering an array of web scraping APIs and specialized scraping tools for various domains. Their features include a vast pool of data centers, and mobile, and residential proxies, catering to a wide range of scraping needs. Brightdata is particularly noted for its high-end proxies and is regarded as a premium web scraping software.
The platform offers dedicated scrapers for specific websites, including Google, Yelp, and Zillow, which contributes to its high success rate in scraping across various websites.
However, Brightdata’s services are priced at the higher end of the spectrum, making it more suitable for companies with larger budgets. Additionally, some users have reported challenges with customer support and user experience, particularly regarding the dashboard’s complexity and potential lag between the front and backend, suggesting issues with API and frontend synchronization.
Crawlbase Scraper API
Crawlbase Scraper API offers a robust web scraping solution, ideal for both businesses and developers. Its key feature is the ability to extract data from any website through a single API call, streamlining the web scraping process. The API is further enhanced by the inclusion of rotating data centers and residential proxies, which are critical for scaling, scraping activities, and overcoming website blockages.
This tool is particularly suitable for those who are either building their scrapers or need large-scale scraping operations without triggering website access restrictions. Crawlbase API’s efficiency in data extraction makes it a practical choice. They offer a free trial with 1000 requests, enabling users to evaluate its features before committing to a paid plan.
Key benefits include comprehensive documentation for various programming languages and exceptional support for any queries or issues. Additionally, its affordability makes it a competitive option in the market. However, it’s worth noting that a basic understanding of coding is beneficial to fully utilize the API’s capabilities.
Scraper API
ScraperAPI is an efficient online tool for web scraping, offering the capability to scrape any site with just a single GET request. This service includes both data center and residential proxies, which are particularly useful for those with their scraping tools, helping to prevent blocks during large-scale scraping operations. ScraperAPI gives free credits whenever you sign up for the first time. Its documentation is comprehensive, ensuring ease of use. Additionally, ScraperAPI is known for its responsive and helpful support.
However, users should be aware of some limitations. The service has been noted for inconsistent uptime, with occasional server crashes. Additionally, scraping complex websites such as Amazon and Indeed can be more costly, consuming more scraping credits per page. There are also certain websites, like Indeed and Google, where the tool might face difficulties in scraping effectively.
Check Out: How Scrapingdog is a Perfect Alternative for Scraper API
3 No-Code Web Scraping Tools
Parsehub
Parsehub, designed to cater to non-developers, is a web scraping tool available as a desktop application. It offers a free version with basic features, making it an attractive option for beginners in web scraping or those who are not ready to commit fully. For enterprise-level clients requiring more advanced functionalities, Parsehub provides subscription plans that unlock a wider range of features.
The advantages of Parsehub include the ability to schedule web scraping tasks, which is particularly useful for regular data extraction needs. Additionally, they offer free web scraping courses and guides, aiding users in quickly getting up to speed with the tool’s capabilities.
On the flip side, Parsehub does have a somewhat steep learning curve, despite its no-code approach, which might require some time for users to fully grasp. Also, the availability of support is tiered, which means that the level of assistance you receive may depend on your subscription plan.
Octoparse
Octoparse is another user-friendly no-code web scraping tool that shares similarities with Parsehub. It features a straightforward point-and-click interface, eliminating the need for any coding expertise. Octoparse sets itself apart with its AI-powered auto-detect functionality, which simplifies the data extraction process by not relying on traditional methods like HTML selectors.
Key advantages of Octoparse include the ability to effectively extract data from complex web elements, such as dropdown menus. Additionally, it offers flexibility in how scraping tasks are run, giving users the choice to execute them either on the cloud or locally on their device.
However, like Parsehub, Octoparse also presents a steep learning curve that might require a significant investment of time to overcome. Additionally, the level of customer support provided is somewhat limited, which might be a consideration for users who may require extensive assistance.
Lobstr.io
Lobstr offers a suite of ready-made tools accessible online, designed to help individuals and companies automate repetitive online actions and collect data efficiently. Their services include collecting personal data from social networks, gathering price and stock data from e-commerce sites, and various other automation tasks to support personal and business growth. The platform aims to be a no-brainer investment for companies of all sizes with its structured and affordable pricing model.
They do have easy-to-use APIs too that allow teams to collect data programmatically without the hassle of maintaining individual scrapers. They support multiple programming languages and offer prebuilt integrations for popular services like Salesforce and Zapier.
While no-code web scraping tools are user-friendly and accessible for those without programming skills, they do have limitations compared to web scraping APIs, which are important to consider:
| Feature | No-Code Web Scraping Tools | Web Scraping APIs |
|---|---|---|
| Customization and Flexibility | Limited; often rely on predefined templates and workflows. | High; allows tailored data extraction and manipulation. |
| Handling Dynamic/JavaScript-Heavy Sites | Might struggle with dynamic content and heavy JavaScript. | Generally more capable, especially those that render JavaScript. |
| Scalability | Not as scalable; limited by GUI-based processing. | Highly scalable; can handle large volumes of data and simultaneous requests. |
| Speed and Efficiency | Slower due to more manual configuration. | Faster and more efficient; can be integrated directly into scripts or applications. |
| Error Handling and Robustness | Limited advanced error handling capabilities. | More robust; better equipped to handle network errors, server failures, etc. |
| Dependency on Tool’s UI/Updates | High; dependent on the interface and tool updates. | Lower; can be quickly adjusted in code for website changes. |
For users with no coding experience, but want to scale their data extraction process, integrating web scraping APIs with platforms like Airtable offers a practical approach. This method bridges the gap between the power of APIs and the simplicity of no-code tools.
I wrote a guide that demonstrates this approach, specifically focused on scraping LinkedIn job data without the need for coding. The guide walks through the process step-by-step, making it accessible even for those without a technical background. This way you can scrape almost any website just like we did for LinkedIn here.
Web Scraping Tools for SEO
Screamingfrog

Screamingfrog is a renowned tool in the SEO community, known for its comprehensive web scraping capabilities, specifically for SEO purposes. This desktop application, available for Windows, Mac, and Linux, stands out for its ability to perform in-depth website crawls. It’s particularly adept at analyzing large sites, and efficiently extracting data such as URLs, page titles, meta descriptions, and headings.
Key features of ScreamingFrog include the ability to identify broken links (404s) and server errors, find temporary and permanent redirects, analyze page titles and metadata, discover duplicate content, and generate XML sitemaps. It’s also useful for visualizing site architecture and reviewing robots.txt files.
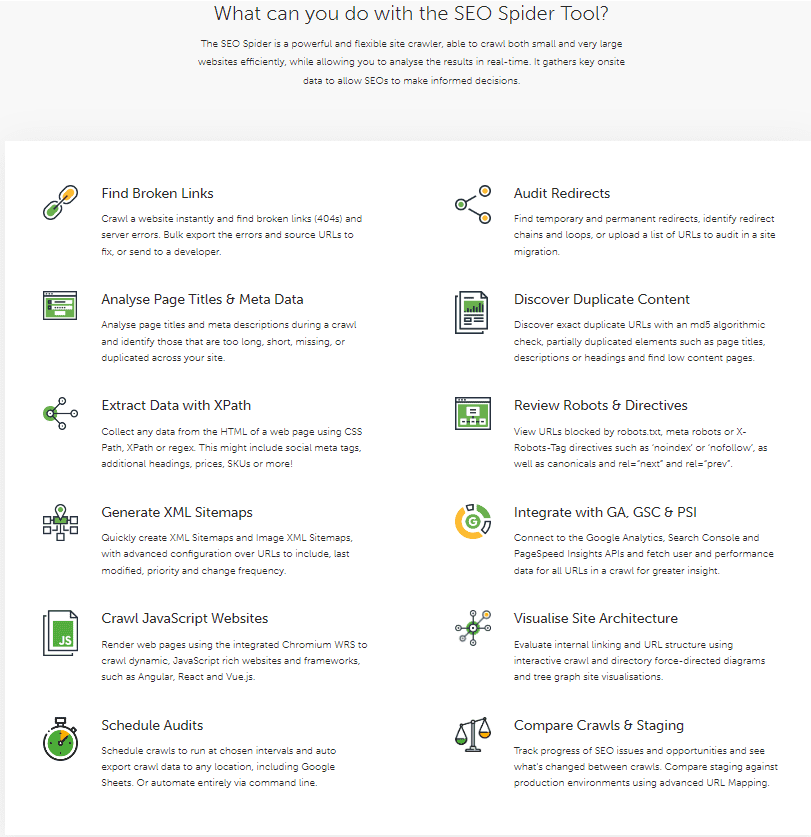
Screamingfrog can also integrate with Google Analytics, Google Search Console, and other SEO tools, enhancing its data analysis capabilities. This integration allows for a more comprehensive SEO audit, covering aspects like internal linking and response time.
Sitebulb
Sitebulb is a desktop-based web crawling and auditing tool and is also highly regarded in the SEO community for its comprehensive and user-friendly features. Available for both Windows and Mac users, Sitebulb provides an intuitive interface that simplifies the process of conducting in-depth SEO audits.
The tool excels in offering a wide range of insightful SEO data. It thoroughly analyses various aspects of a website, including site structure, internal linking, HTML validation, and page speed issues. Sitebulb’s capability to identify areas such as broken links, redirects, and duplicate content makes it an invaluable asset for SEO professionals.
One of the standout features of Sitebulb is its detailed reporting and visualizations, which offer deep insights into the data it collects. This helps in understanding complex site architecture and SEO issues more clearly. The reports generated are not only comprehensive but also easy to interpret, making them useful for both SEO experts and those new to the field.
While tools like ScreamingFrog and Sitebulb are excellent for crawling and scraping content from individual web sources, it’s important to note their limitations. These tools are not designed for data extraction at large scales. They are best suited for specific use cases in SEO, such as auditing a single website’s SEO performance or analyzing its content structure.
Their functionality is primarily focused on SEO tasks and may not be as effective for broader data scraping needs that require handling multiple sources or large datasets simultaneously.
Note that if you run into compatibility issues with Sitebulb on macOS Sequoia, you could downgrade it to macOS Sonoma and then try running the tool again.
Building a Scraping Tool from Scratch Using Programming Language
For those who seek the utmost flexibility and control in web scraping, building custom tools using programming languages is the best way. This approach is especially suited for tech-savvy individuals or teams with specific scraping needs that go beyond what pre-built tools offer.
It involves selecting a programming language that aligns with your project requirements and using its respective libraries and frameworks for scraping tasks. While this path offers greater customization, it also comes with its share of challenges and learning curves.
The most popular languages for web scraping include:
1. Python: Known for its simplicity and readability, Python is a favorite for web scraping due to its powerful libraries like BeautifulSoup, Scrapy, and Selenium. These libraries offer various functionalities for parsing HTML, handling JavaScript, and automating browser tasks.
2. JavaScript: With Node.js and frameworks like Puppeteer and Cheerio, JavaScript is ideal for scraping dynamic websites. It’s particularly useful for sites that heavily rely on JavaScript for content rendering.
3. Ruby: Ruby, with its Nokogiri library, is another good choice for web scraping, offering straightforward syntax and efficient data extraction capabilities.
4. PHP: While not as popular as Python or JavaScript for scraping, PHP can be used effectively for web scraping with libraries like Goutte and Guzzle.
Each language has its strengths and is suitable for different types of scraping tasks. However, as said earlier there are some limitations associated with building these scrapers and therefore I have listed them below in the table.
| Feature | No-Code Web Scraping Tools |
|---|---|
| Customization and Flexibility | Limited; often rely on predefined templates and workflows. |
| Handling Dynamic/JavaScript-Heavy Sites | Might struggle with dynamic content and heavy JavaScript. |
| Scalability | Not as scalable; limited by GUI-based processing. |
| Speed and Efficiency | Slower due to more manual configuration. |
| Error Handling and Robustness | Limited advanced error handling capabilities. |
| Dependency on Tool’s UI/Updates | High; dependent on the interface and tool updates. |
Conclusion
Web Scraping offers a diverse range of tools and methodologies, each catering to different needs and skill levels. From no-code solutions ideal for beginners and non-developers to the more advanced web scraping APIs for those with programming expertise, there’s a tool for every scenario.
While no-code tools provide an accessible entry point into web scraping, they have their limitations in terms of scalability and flexibility compared to more robust web scraping APIs and custom-built tools using programming languages.
For SEO purposes, specialized tools like ScreamingFrog and Sitebulb offer targeted functionalities but are not designed for large-scale data extraction. They limit themselves to SEO only.
Remember, the choice of a web scraping tool should align with your technical skills, the scale of data extraction needed, and the specific tasks at hand. Whether you’re a marketer, developer, or researcher, the web scraping landscape offers a tool that can fit your unique data-gathering needs.
- Get link
- X
- Other Apps
- Get link
- X
- Other Apps
Comments
Post a Comment